


Generating Star Schemas from Data Vault
Our RootCloud Platform provides an easy way for users to construct their enterprise data vault to generate dimensional star schemas…


Our RootCloud Platform provides an easy way for users to construct their enterprise data vault. With it, our users can manage data vault’s table schema, ingest IoT data, incrementally import and transform IT data from external systems, connect BI tools to it, and build applications directly with its APIs. One special sauce we have is the direct integration of OT and IT data. As long as the “link” between OT and IT is available in the vault, our platform can automatically integrate them together to serve business queries.
There’s one caveat: data vault is not intended to be queried directly. Data vault brings many benefits to the table, however easy and fast querying is never one of those. Its creator Dan Linstedt recommends adding Kimball dimensional modeling data marts as outputs specifically to serve business queries. This approach brings the best of the two modeling techniques together. That’s what our system provides.

The data vault serves as the single source of truth within the enterprise. Users can freely pick required entities, relationships, and transaction/event tables to create a star schema easily. The process is also super lightweight (mostly star schema is just composed of views on top of data vault tables) so that users can create as many star schemas as desired. That enables the agility necessary to serve the always-changing business requirements.
There are many advantages of this architecture:
New data sources can easily be added and ingested to data vault without impacting the data marts.
Since all the data is in the data vault, dropping or recreating data marts is super easy.
Different teams can work together, in parallel, on different star schemas, based on the same data vault. No team is going to be disrupted by other teams.
High agility is achieved. PoC can be done easily by simply creating a new star schema, and populating data from the data vault. The result is either checked and published or rejected and scraped.
Business rules are implemented and governed in the business vault and, hence can be shared by all teams.
From Data Vault to Star Schema
So how did we achieve it?
As we use dbt internally for populating the data vault, naturally we also want to use dbt to create and populate data marts. We have created a few dbt macros for generating star schema dimension and fact tables from data vault constructs. This conforms to our automated, repeatable, and modular patterns.
In our data vault, we model business entities as hub and satellite(s) combo, and relationship as link and satellite(s) combo. For transactional events or IoT measurement data, we use transactional links.

In a star schema generated, dimensions are based on entities, and facts are based on transactional links. Relationships are not mapped directly but are used to connect entities for snowflake-style usage or for denormalizing into flattened facts.
For dimension tables, we provide two flavors: with and without history tracking. You get to choose between SCD1 and SCD2 for individual dimensions (of course, our query API handles that for users automatically). In order to efficiently generate dimension tables, we take advantage of point-in-time tables (PIT). By periodically and incrementally generating PIT, our star schema dimension tables can simply be views defined on PITs together with their base hubs/satellites. This is key to our users as they get SCD2 for free, if and when needed.
Based on the awesome AutomateDV, below is the dbt macro for generating a dimension table using PIT:
{%- macro dimension(src_pk, src_nk, src_extra_columns, satellites, exclude_columns, src_ldts, source_model, pit) -%}
{{- dbtvault.check_required_parameters(src_pk=src_pk, src_nk=src_nk,
src_ldts=src_ldts,
source_model=source_model) -}}
{{- dbtvault.prepend_generated_by() }}
{{ adapter.dispatch('dimension', 'dbtvault')(src_pk=src_pk, src_nk=src_nk,
src_extra_columns=src_extra_columns,
satellites=satellites,
exclude_columns=exclude_columns,
src_ldts=src_ldts,
source_model=source_model,
pit=pit) -}}
{%- endmacro -%}
{%- macro default__dimension(src_pk, src_nk, src_extra_columns, satellites, exclude_columns, src_ldts, source_model, pit) -%}
{%- set source_cols = dbtvault.expand_column_list(columns=[src_pk, src_nk, src_extra_columns]) %}
{%- set include_columns = [] %}
{%- set exclude_columns = exclude_columns | map("lower") | list %}
{%- for col in source_cols -%}
{%- if col | lower not in exclude_columns -%}
{% do include_columns.append(col) %}
{%- endif %}
{%- endfor %}
{%- set pit_name = pit['pit_name'] -%}
{%- set pit_pk = pit['pk']['pk'] -%}
{%- set pit_ldts_name = pit['ldts'] %}
{%- set pit_as_of_date_name = pit['as_of_date'] %}
SELECT
{{ dbtvault.alias_all(include_columns, pit_name | lower ~ '_src') }}
{%- if pit_as_of_date_name %}
,{{ pit_name | lower ~ '_src' }}.as_of_date as {{ pit_as_of_date_name }}
{%- endif %}
{%- for sat_name in satellites -%}
{%- if 'extra_columns' in satellites[sat_name] and satellites[sat_name]['extra_columns'] -%},
{%- set sat_extra_columns = satellites[sat_name]['extra_columns'] %}
{{ dbtvault.alias_all(sat_extra_columns, sat_name | lower ~ '_src') }}
{%- endif -%}
{%- endfor %}
FROM {{ ref(pit_name) }} AS {{ pit_name | lower ~ '_src' }}
{%- for sat_name in satellites -%}
{%- set sat_pk_name = (satellites[sat_name]['pk'].keys() | list )[0] -%}
{%- set sat_ldts_name = (satellites[sat_name]['ldts'].keys() | list )[0] -%}
{%- set sat_deleted_name = (satellites[sat_name]['deleted'].keys() | list )[0] -%}
{%- set sat_pk = satellites[sat_name]['pk'][sat_pk_name] -%}
{%- set sat_deleted = satellites[sat_name]['deleted'][sat_deleted_name] %}
LEFT JOIN {{ ref(sat_name) }} AS {{ sat_name | lower ~ '_src' }}
ON {{ sat_name | lower ~ '_src' }}.{{ src_pk }} = {{ pit_name | lower ~ '_src' }}.{{ pit_pk }}
AND {{ sat_name | lower ~ '_src' }}.{{ sat_ldts_name }} = {{ pit_name | lower ~ '_src' }}.{{ sat_name ~ '_' ~ pit_ldts_name }}
{% endfor %}
{%- endmacro -%}and the usage of this macro:
{{ config(
schema = "mart",
materialized = "view",
) }}
{%- set yaml_metadata -%}
source_model: hub_ent_equip
src_pk: hk_ent_equip
src_nk:
- source_column: equip_id
alias: equip_id
src_extra_columns:
- source_column: id_pit_ent_equip
alias: id_ent_equip
pit:
pit_name: pit_ent_equip
pk:
pk: hk_ent_equip
ldts: load_datetime
as_of_date: effective_datetime
exclude_columns:
- hk_ent_equip
src_ldts: load_datetime
{%- endset -%}
{% set metadata_dict = fromyaml(yaml_metadata) %}
{{ dbtvault.dimension(source_model=metadata_dict['source_model'],
src_pk=metadata_dict['src_pk'],
src_nk=metadata_dict['src_nk'],
src_extra_columns=metadata_dict['src_extra_columns'],
satellites=metadata_dict['satellites'],
exclude_columns=metadata_dict['exclude_columns'],
src_ldts=metadata_dict['src_ldts'],
pit=metadata_dict['pit']) }}For fact tables, two options are available. For simple cases, say a transaction line item data persisted in a transactional link, the corresponding fact table is simply incrementally synchronized from the link table. The line items, products, and users referenced in the data all become the fact table’s foreign references to different dimension tables. This is a simple 1-to-1 mapping from data vault to the generated star schema.

For more complicated cases, usually, a chain of links and hubs need to be joined first to enrich the transactional links with the required dimensions. In this case, we allow specifying the “join chain” and the intended dimensions. Essentially, it creates a “denormalized” fact table. An example would be IoT data, which usually comes with just the sensor ID. Of course, we can go with snowflake, but we are really more star guys. By specifying the “join chain” from the sensor ID to its belonging equipment, maybe also further from equipment to the belonging organization, location, and work order, it is very easy to populate a required fact table to serve different business needs.
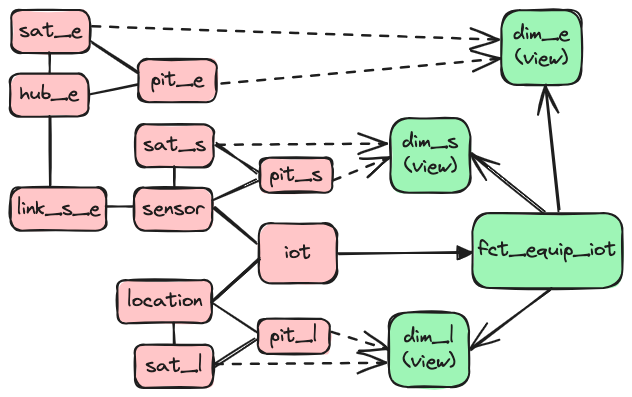
Remember since the data vault is the source of truth, any time a new business requirement comes in, we can either update an existing star schema suitable for the purpose, or simply drop-recreate one, or just go creating a new star schema. Either way, all other star schemas are not affected.
Unified View of Data
One of the most important things about a data warehouse is a shared understanding of the business entities and the business processes. This is largely served by the data vault. But what about the dimensional data marts generated from it? Wouldn’t a separate set of data marts conflict with that?
The dimension tables we generated are simply views on top of business entities (hubs and their satellites). Since entities are shared and are the single source of truth, all the dimension tables are guaranteed to be consistent even though different users have their own set of dimension view(s). Essentially, all users are using the same shared dimension (data).
As for fact tables, allowing different users to share physical fact tables has many downsides. Any change to the fact tables would affect someone else, that’s disruption we don’t want to have. To enable full agility, different users must have their own, isolated fact tables. Does that conflict with the goal of having a standard understanding of the business? I believe not, as long as the underlying is the shared data vault, isolated fact tables provide the necessary view of data to different presentation and/or visualization level requirements. And that’s the main point of having multiple data marts.
Star Schema Query Performance
There’s one thing worth mentioning. Originally, we used data vault’s hashkey directly in the generated star schemas. It works fine but the performance suffers as the table size increases. This is mostly due to the hashkey’s length (we use SHA256 which ends up as 128-byte long). For non-trivial fact tables, this became an issue both for the increased table size and the slowed-down query performance.
We have chosen to generate an integer sequential ID for data vault constructs, which is used only in the generated data marts (data vault part always uses hashkey). The sequence ID is stored together with the hashkey in hubs. In the generated star schema dimension and fact tables, the hashkey is removed and only the sequence ID is included. This improves the query performance at least by an order of magnitude.

The creation of the sequence ID column can be standardized in the data vault construct dbt SQL file, like the following:
{% set sequence_id = 'id_ent_equip' %}
{{ config(
schema = "er",
materialized = "rc_incremental",
upsert_by = "hk_ent_equip",
timestamp_field = "load_datetime",
ignored_dest_columns = sequence_id
) }}
{% call set_post_sql_header(config) %}
alter table {{ this }} add column if not exists {{ sequence_id }} integer generated always as identity;
create unique index if not exists {{ sequence_id }}_{{ this.table }}_true_integer on {{ this }} ({{ sequence_id }});
{%- endcall %}
{%- set yaml_metadata -%}
source_model: stg_ent_equip
src_pk: hk_ent_equip
src_nk:
- equip_id
src_ldts: load_datetime
src_source: record_source
{%- endset -%}
{% set metadata_dict = fromyaml(yaml_metadata) %}
{{ dbtvault.hub(src_pk=metadata_dict["src_pk"],
src_nk=metadata_dict["src_nk"],
src_ldts=metadata_dict["src_ldts"],
src_source=metadata_dict["src_source"],
source_model=metadata_dict["source_model"]) }}Conclusion
With an automated, repeatable, and modular pattern, we made data vault’s integration with Kimball dimensional data marts easy. This separation of concerns serves the business pretty well, as multiple teams get to work together, in parallel, on the same data vault. The evolution of the data vault typically does not affect the data marts (that’s what data vault is designed for), and the business reporting and analytics teams can iterate quickly and independently. And that is really the goal of using data vault.