


Maintaining Two Timelines with Data Vault
In business architecture, there are at least two views: the real-world view and our system’s view.


The Two Timelines
The first principle of business architecture is never to discard information. Save all business information forever and keep track of all changes. This decouples the data processing from the data ingestion, so we are free to start a new analytical data processing or reprocess an existing one at any time with any slice of history.
In business architecture, there are at least two views: the real-world view and our system’s view. For example, a business contract is signed in the real world, and at a later time, the record of this contract enters our system. There is always some delay between the time the actual event occurs and the time our system records it.
| System Load Date | Contract Num. | Business Date | Amount |
| ---------------- | ------------- | ------------- | ------ |
| 2023-11-02 | 101 | 2023-11-01 | 10,000 |
| 2023-11-16 | 101 | 2023-11-15 | 20,000 |In the example above, in the real-world contract 101 became effective on 2023–11–01 for an amount of 10K. Later, the amount of it was changed to 20K, effective from 2023–11–15. Since contract data is loaded into the system daily, the system load date is typically on the next day.
The two different worlds of view each have their separate timelines. Do we need to care about both timelines? Well, that depends on your requirements. Generally, there are two categories of questions we have to answer:
What is contract 101’s amount, right now? (20K)
What was contract 101’s amount in the system on 2023–11–10? What was it on 2023–11–20? (10K and 20K, respectively)
The first question certainly needs to be answered, as it pertains to actual business. The latter is typically for auditing purposes. If you do need to answer the second kind of question, then you need to maintain the second timeline for the system’s view.

However, even if you don’t have requirements for the second kind of question right now, how can you be sure your business users won’t change their minds later? Since the system timeline is unrecoverable after the initial ingestion process is done, we’d better keep it right from the beginning in any way.
So, how do we maintain two timelines?
For each event entering our system, we need to record both:
When this event happens in the real world.
When this event is recorded by our system.
The ability and flexibility we want is to be able to answer both categories of questions above. That’s what we want to enable in the architecture.
Late-Arriving Data
At this point, you might wonder whether we can just use the system’s timeline to represent the real-world timeline. The answer to that comes down to the problem caused by late-arriving data doing retroactive updates.
| System Load Date | Contract Num. | Business Date | Amount |
| ---------------- | ------------- | ------------- | ------ |
| 2023-11-02 | 101 | 2023-11-01 | 10,000 |
| 2023-11-16 | 101 | 2023-11-15 | 20,000 |
| 2023-11-22 | 101 | 2023-11-01 | 15,000 |Let’s expand the same contract example a bit. On 2023–11–22, a correction was made to change contract 101’s amount to 15K effective from 2023–11–01. This is the so-called late-arriving data doing retroactive updates. The reason might be a correction to human error or for some business reason, but it does not matter. From the real-world view, once the correction was loaded into the system, contract 101’s amount on Nov 1 should be 15K, no longer be 10K.
You can think of the real-world view as the system’s “as-of-now” view. You’ll also notice below the system view as of 2023–11–30 changes because the correction was applied on 2023–11–22.

If we only keep system load dates and treat them as real-world business dates, we will mistakenly identify contract 101’s amount to be 10K from 11–02 to 11–16, 20K from 11–16 to 12–01, and 15K from 12–01 to now. This is not the expectation of correcting the amount to be 15K from 11–02 to 11–16.
Note that many source business systems do not provide real-world business dates, and the best we can get (and approximate) is using our system’s load dates as the business dates. In these cases, this is the best we can do. For other cases, when business dates are indeed available from the source systems, keep and use them.
One more thing about late-arriving data. There might be downstream data processing (directly or indirectly) affected by the late-arriving data, which needs to be identified and reprocessed automatically. All the affected time ranges as well as all the existing results processed with data from those time ranges need to be identified and reprocessed.
Maintaining Two Timelines with Data Vault
Below are the standard table schemas for all our data vault constructs. We standardize not only the schema but also all the table and column names.
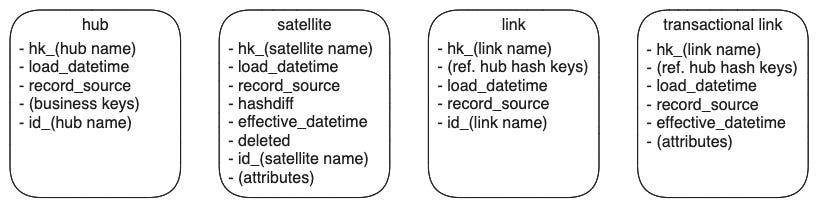
The system timeline uses the data vault’s standard load_datetime column. For the real-world business timeline, column effective_datetime is added to the satellite (transactional links do not have associated satellites hence are directly added to the links themselves).
As mentioned in the previous section, whenever the source systems do provide a business timeline, we recommend using that. Otherwise, the best is to use the system timeline to approximate it. If users do not write values to effective_datetime, our system automatically uses the value from load_datetime to write it.
That finishes the normal ingestion flow. What about the late-arriving data mentioned above?
Remember in a data vault, satellite data is compressed in SCD2 structure. Because of that, things get a little tricky because we need to consider the chronologically immediate neighbors, both the previous and the next, to decide what and how to insert into satellites.
Let’s use a simple example. Originally, both T1:(1) and T3:(3) were already processed and entered into the data vault. Since satellites are in SCD2 structure, if T1:(1) and T3:(3) have the same value, only T1:(1) is saved in the satellite. On the other hand, if they have different values, both T1:(1) and T3(3) are saved in the satellite. T2:(2) is the late-arriving data, which is chronically between T1 and T3.

There are 5 possible scenarios to be considered:
1. Originally both T1:(1) and T3:(3) are A, hence only one row in the satellite. The late-arriving T2:(2)=A is the same as both, hence only one row in the satellite at the end.
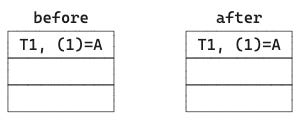
2. Originally both T1:(1) and T3:(3) are A, hence only one row in the satellite. The late-arriving T2:(2)=B is different from both T1 and T3, hence we have to insert two rows, one for T2:(2)=B and one for T3:(3)=A to correctly save the history in the satellite. There are 3 rows at the end.

3. Originally T1:(1) is A and T3:(3) is C, hence two rows are saved in the satellite. The late-arriving T2:(2)=A is the same as T1, hence there’s no need to insert a new row for T2. There are still two rows at the end.
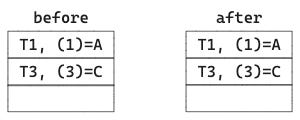
4. Originally T1:(1) is A and T3:(3) is C, hence two rows are saved in the satellite. The late-arriving T2:(2)=B is different from T1:(1)=A and also different from T3:(3)=C, hence we need to insert a row for T2. There are three rows at the end.

5. Originally T1:(1) is A and T3:(3) is C, hence two rows are saved in the satellite. The late-arriving T2:(2)=C is different from T1:(1)=A but the same as T3:(3)=C. We have to insert a row for T2. There are three rows at the end. Note that T2:(2)=C and T3:(3)=C have the same value and normally should be compressed to leave only one row for T2. However, to “never discard information”, we choose to keep them both.

Patrick Cuba has an awesome article on how to use an extended record-tracking satellite (XTS) to support this processing.
As mentioned in the previous section, after T2:(2) is processed and entered into the satellite, any downstream processing affected by this change needs to be identified and reprocessed.
Querying the Two Timelines
With the two timelines maintained in our data vault, how do we query them?
Remember the two categories of questions we need to answer:
What is contract 101’s amount, right now?
What was contract 101’s amount in the system on 2023–11–10? What was it on 2023–11–20?
We let users choose with which to generate dimensions. Users can generate different versions, probably one for the business timeline view and another for the system timeline view.
For business-view dimensions, our system first generates the underlying business-view PIT tables. We use snapshot PIT tables, so we first group by the column effective_datetime, and within each group, we select the one row with the latest load_datetime value. So, for each snapshot date, the PIT table rows all point to the correct satellite row based on the business timeline. Finally, the dimension is created by joining the PIT tables to the base hub and satellite tables, with the column effective_datetime included as the time base.
For system-view dimensions’ PIT tables, the only difference is that we pre-filter the data with snapshot dates on the column load_datetime. This ensures that for each snapshot date, only the system's viewable data is present. Then we follow the same process of generating business-view dimensions.
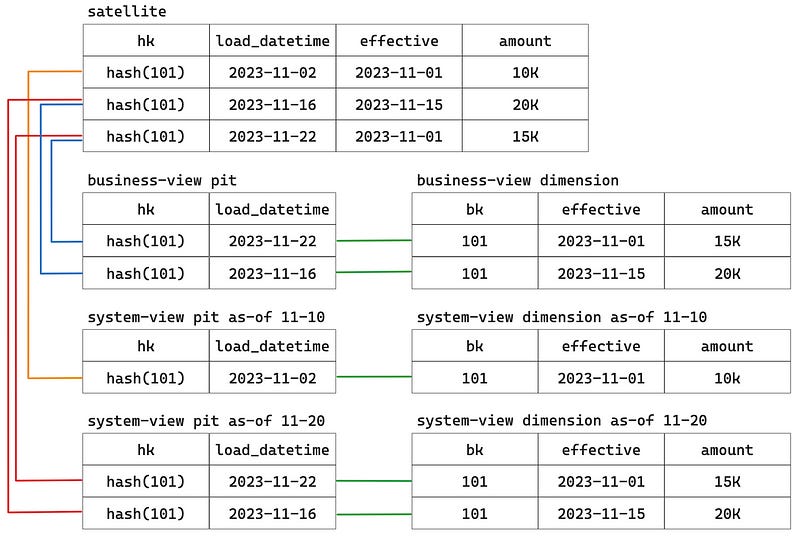
For facts (transactional links), the process is the same. Therefore, users can choose to use the business-view version to answer the first question and to use the system-view version to answer the second question.
Note that the business-view PIT tables do need to be regenerated for the affected parts, which can be done incrementally whenever there is late-arriving data. However, the system-view PIT tables do not need to be regenerated because load_datetime is always monotonically increasing.
Conclusion
Unlike the TVA, we don’t have ever-increasing multiverse timelines to manage or prune. However, we do have two “sacred” timelines to maintain. The “real-world” timeline serves the business requirements, and keeping the full history of this timeline allows for the retrieval of historical values. The “system” timeline serves the auditing requirements to ensure that retroactive updates do not go rogue. Maintaining the two timelines in a data vault can be easily done with an automated, repeatable, and modular pattern applied. Together with systematic star schema generation from the data vault, it serves as a solid foundation for building analytical solutions. Let the Time-Keepers protect your timeline for you.