
Serverless IoT Analytics with OpenWhisk Part 2 — How to structure functions?
This is the second part of a series.


This is the second part of a series.
My first take on implementing Watson IoT Analytics with OpenWhisk was pretty minimum in function. Now I’m going to start iterating. Here’s the event processing flow in Watson IoT Analytics.

An incoming event first goes through the rule evaluation and then a stateful processing. If the event passes through the rule filtering, it then checks if anything needs to be triggered and then triggers it. Part 1 implements just the rule evaluation and webhook posting, all within a single OpenWhisk action.
The next question is, how to structure my function (or functions) for adding those conditional branching logic?
Latency
There are at least 3 options available[1]. To answer the question, I need to first understand the latency of each option.
Inline: all functions are put in a single OpenWhisk action.
Sequence: each function is an action and an OpenWhisk sequence is used to chain them together.
OpenWhisk npm package: each function is an action and a main controller action uses the npm package to invoke and coordinate them.
I tested the 3 options with 2 different setting. The first setting is just one level of function call (for the inline option):
// increment.js
function main(params) {
params.value = params.value || 0;
return {value: inc(params.value)};
}function inc(value) {
return value + 1;
}The other is 10 nested level (for the inline option):
// inline-10-level.js
function main(params) {
params.value = params.value || 0;
return {value: inc(inc(inc(inc(inc(inc(inc(inc(inc(inc(params.value))))))))))};
}function inc(value) {
return value + 1;
}for sequence option:
// sequence-main.js
function main(params) {
return params;
}----> wsk action update sequence-1-level sequence-main,increment --sequence> wsk action update sequence-10-level sequence-main,increment,increment,increment,increment,increment,increment,increment,increment,increment,increment --sequencefor npm package option 1 level (it’s too ugly to show the 10 level code…):
// npm-1-level.js
var openwhisk = require('openwhisk');function main(params) {
params.value = params.value || 0;
var p = {name: 'increment', blocking: true, result: true, params: params};
var ow = openwhisk();
return ow.actions.invoke(p).then(result => {
return {value: result.response.result.value};
});
}Let’s see the comparison result:
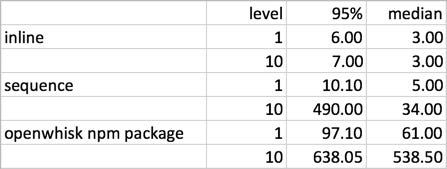
No surprise here. Inline option being the fastest, sequence next, and npm package the worst. The sequence one has bigger variance though.
As expected, inline option does not differ much in latency (1 v.s. 10 levels).
It’s understandable each action in a sequence adds some overhead. But it does add up. Also, the more actions in a sequence, the bigger variance it has.
OpenWhisk npm package uses OpenWhisk REST API to invoke actions, so each action invocation incurs overhead like network and authentication. It adds quite some latency.
Note that the overhead in latency for both sequence and npm package options are fixed (per action). They are not proportional to action duration[2]. My action is short and fast (a few milliseconds) so the overhead seems especially severe. But if your action is on the seconds level, it probably is not a big issue as long as you use just a few nested levels.
What does this tell us? Unless your actions are all shorter than 10 ms, you don’t need to worry much about the latency overhead introduced by using either sequence or the npm package. Using sequence is faster than using npm package, but as I’ll show later, sometimes we have no choice because OpenWhisk sequence is limited (like you can’t short circuit in the middle, or you can only have one flow).
On the other hand, this does not suggest to blindly transform existing code to FaaS world, like one-to-one function to action mapping. That would be very very wrong. The unit of “function” should be anything related to the exposed “service”. There’s no point in further breaking down that unit on FaaS.
Artifact Size
Out of curiosity, I wonder whether the artifact size would affect actions’ performance.
I tried using a 14MB zipped nodejs action. The normal duration stays pretty much the same, but those periodic spikes differ. For this 14MB size the spikes are around 2000 ms, compared to around 50 ms for the original version.
Since the spikes happen pretty consistent (once every 50 runs), it’s not entirely correct to say they don’t affect runtime performance. If you have a large artifact size, you should expect to have 2% chance to hit a slow run[3].
Iteration #2
I’ve made some changes to my action in part 1:
I’ve split the webhook posting into its own action. This is because the webhook posting is intended to be a general ”service” which can be used somewhere else.
If no event exceeds our threshold, no invocation is made to the separate webhook action. No unnecessary cost.
BTW, the webhook action can accept batch of events. Cost saving again.
Webhook body can now be customized, similar to Watson IoT Analytics.
Rule/webhook metadata are extracted out of the code, which opens the door for being passed in as action parameters.
Note that the latency of this version does not differ from last one.
Notes
Another option is to use Message Hub topics as queues between actions. Each action publish it outcome for downstream actions to consume. This option is considerably more cumbersome to setup and obviously not fast. I consider it more of external asynchronous integration.
I added a sleep inside my action to make it longer (a few seconds). In that case, the latency overhead stays the same as without the sleep introduced.
During the latency tests, I noticed one thing very interesting. Normally my function’s duration is around 3 ms, but it jumps to around 50 ms once every 50 invocations. I tried increasing the invocation rate from 1 event per 200 ms to 1 event per 1 ms. Both showed the same behavior. I guess some kind of caching is based on counts?
Originally published at bryantsai.com on April 26, 2017.