
Optimize Data Lake Layout to Support Multiple Ordering
There is a way for a data lake to be physically clustered and sorted by multiple columns at the same time.


Imagine a million excavators each sending one message every few seconds. That's 10GB every few seconds and a few TB every hour. And we must never delete the data.1 So, we use Apache Hudi to store the data archives. It serves many batch data processing pipelines. These data pipelines have their own data loading patterns. Some analyze certain kinds of excavators. Some only analyze excavators within specific cubic capacity (CC) ranges. Some analyze the excavator activity within specific areas.
But there's one thing in common: they are not fast. Most pipelines run in hours. They read large volumes of data and spend most of the time in the reading of data files.
The problem is that most data pipelines read ALL the data first to filter the needed parts. It's impractical to have duplicated data sets with different partitioning schemes and clustering layouts because of the size and the corresponding huge cost.2
But, we do have many frequently-running data loading and querying jobs. They keep reading the same complete data set over and over again while most only need a partial of it. Is there a better way?
The Storage Model
We partition our excavator data by day. The record key includes the excavator ID and the timestamp.
At first, we employed the bucket hashing clustering strategy3, with the excavator ID as the bucket field. This is suitable for retrieving individual excavator data as we only need to read one bucket (out of 128, our configured bucket number). But this is not so good for loading many excavators matching some criteria. By definition, hashing distributes excavators among the buckets evenly. On average, we could expect that most large data pipelines end up reading all the buckets.
The column stats index4 does not help either. It can only help skip reading files without a match. When most of the files indeed contain some matched excavators, there's nothing the data skipping can do.
Fortunately, Apache Hudi does have a clustering feature that can help.
Data Clustering
Apache Hudi's clustering5 is a data layout optimization technique. It stitches together smaller files and also orders the data by sort key to enable data locality.
Let's say we have a table with 2 columns A and B. We choose (A, B) as the clustering key. The clustering split files by the unit of 4 records. Below is a simplified illustration. The records are sorted first by column A and then by column B.

When we query for "A == 2", we only need to read file 3. But, when we query for "B == 2", we have to read all 4 files. Column stats index does help confirm all 4 files do contain matched data, but since it appears in all 4 files, we still need to read all 4 files.
We can see that the first column A dominates the ordering. When we query by only the non-prefix column B, there's not much ordering to use (hence not much locality). It "spreads" out to all files.
So, what we need is a clustering method that can order the data by 2 or more columns, while at the same time preserving the locality for each column alone.
Space-Filling Curve
A space-filling curve is a way of mapping a multi-dimensional space into a one-dimensional space. It can provide the nice "locality" property we desire.
The idea is that if all matched data is closer together on the "curve," sorting by the curve's ordering can put matched data in just a few clustered files.
Let's use the Z-order curve to get an intuition of how it works.
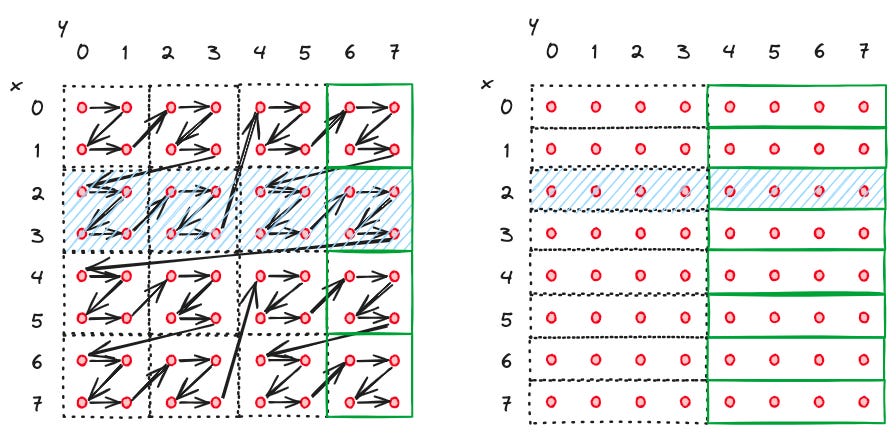
The diagram above shows the comparison of using a Z-order curve and a normal ordering clustering method. A clustering of split size 4 is used. On the left is the Z-order sorted by (x, y), and the right is the normal ordering by (x, y).
If we query for "y == 7," using Z-order only requires reading 4 files (green boxes) while the normal ordering requires reading 8 files. This shows that the use of the Z-order curve does keep the number of data files read small when a non-first column is used alone for querying.
But, when querying for "x == 2", using normal ordering requires reading only 2 files (blue shaded boxes), while using Z-order requires reading 4 files. We are kind of giving up some of the filtering power of the first column for better selectivity for other non-first columns.
Note that the ordering here is not a strict ordering but a rough one. That is not a problem. The main point of using the space-filling curve is the locality it brings to the table. Combined with the column stats indexing, we can find and read the exact data with great efficiency.
If most of your queries only use a single column (or the composite key's prefix), it's better to use the normal ordering method. But if the majority of queries do use different sets of columns, then the space-filling curve method might be worth a shot. It works better with high cardinality columns. It is data-dependent and requires some experiments to find the one best suited for your situation.
In our case, we use the space-filling curve clustering6 with columns vehicle type and ID, timestamp, latitude, and longitude. It serves most frequently run queries pretty well.
Conclusion
For extremely large volumes of data, it might be impractical to have duplicated data sets. We can use space-filling curve clustering to efficiently serve multiple equally frequent query patterns. All major data lakes, including Iceberg, Hudi, and DeltaLake, support space-filling curve clustering. There is also Hilbert curve providing even better multi-dimensional data locality. A lake can have multiple orders at the same time.
Never say never, but customers do get to say it.
Well, this assumption might not be true in all cases. If there is indeed some crazy job running dozens of times a day, it might be cheaper to dedicate a separate, duplicated data set (that is, caching).